2016年年末,Amazon无人超市横空出世。在这家无人超市,店内的相机能够自动追踪你拿取的商品;完成购物后,你无需排队等候收银,只用直接走出超市。
自此之后,阿里和京东也已相继加入战局,先后推出无人超市体验店。一时间,无人超市的概念已实现了大规模普及。
无人超市的“黑科技”到底是什么呢?今天,文摘菌就为大家科普其中最重要的一环——基于计算机视觉技术的物体识别。
首先,让我们分析一下实现无人超市的两大难点。
难点一:把商品加入购物车
超市里的智能货架需要能够追踪到客户拿走了什么商品。我们可以用两个物品识别模型来实现这个功能,一个用来跟踪手部动作以获取被拿起的物品。另一个独立模型则用于检测货架的空间。请看下面的动画,同时使用两个模型可以大大降低误判。

难点二:自动结账
无人超市的需要解决的另一难点是,实现摄像头对物品的一次性识别,这样我们就不需要在结账的时候一件一件物品地扫描过机了。
直接通过购物车里的摄像头检测所买的物品,在你走出超市的那一刻就自动结帐。这个不要太酷哦!
为此,我们需要建立另一个识别模型,用以检测识别物品的种类以及数量。请看下面的动画(即使物品只有部分可见仍能被准确识别出来)。

好了,现在就让我们来具体实现这家无人超市吧。
1、收集数据
我们可以通过下载网上的公开数据集或者自己创建数据集两种方式来收集图片。这两种方法各有利弊。我一般是两种综合使用,比如手部的探测可以使用如Ego Hand数据集(印第安纳大学制作的第一人称视角的手势数据)这样的公开数据集。
这个数据集包含大量手的形状、肤色和动作的变化数据,在实际应用中非常有用。
另一个方面,对于在货架或者购物车里的物品,最好收集自己的数据,因为我们要确保图像数据是来自各个角度的。
在建模之前,建议对数据进行强化,比如使用图像处理库如PIL(Python Imaging Library)、OpenCV(跨平台计算机视觉库)对图片数据进行处理,以产生不同亮度、大小、旋转方向等的额外图片。这样处理能够生成大量新的样本让模型更加稳健。
对于物品检测模型,我们需要对目标物品加上带注释的方框。
我们可以使用 Python开发的labelimg(图片标注工具)来实现并且用Qt(Qt Company开发的跨平台C++图形用户界面应用程序开发框架)开发界面。
这是一个非常好用的工具,使用PascalVOC格式(图像识别和物品分类)创建注释可以很容易用Tensorflow Github里分享的代码生成TFRecord 文件(Tensorflow图像数据格式)。
2、建模
在建模的时候你需要做的一个重大决定就是选择物品检测模型。在COCO数据集上训练过的最新模型如下:
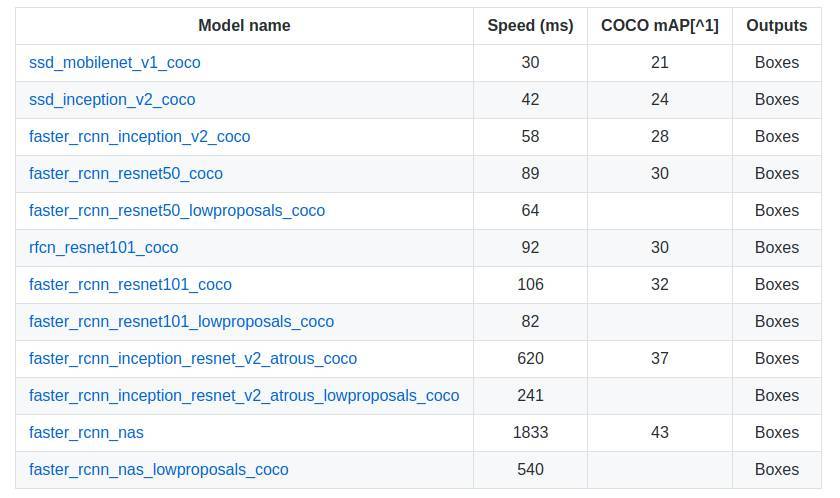
识别速度和准确率之间总是效益相悖难两全的。个人认为对于实时的手部检测,最好使用SSD模型(Single Shot Detector单次激发检测)或者更快的RCNN(区域卷积神经网络)。而对于货架或者购物车里的物品我更愿意使用识别慢一点但准确度更高的模型如Faster RCNN Resnet(快速区域卷积神经网络残差网络)或者Faster RCNN Inception Resnet(快速区域卷积神经网络初始残差网络)。
3、测试和优化模型
在构建完第一个版本的无人超市后,你就要进入漫长的改进阶段了。没有模型是完美的,随着你的测试,你自会发现它的不如意之处。接着你就要用你的直觉来判断,这些不足是否能被消除,以使模型更精准:或许你应该使用另一个模型,又或许,根本没有模型能得到你期望的准确度。如果幸运的话,你只需要增加训练数据的样本量来提升模型的性能。
读完这篇文章,是不是觉得无人超市也没有想象中的那么神奇了呢?当然了,无人超市背后的技术远不止计算机视觉,无人超市的真正落地也依旧存在了各类技术难点——亚马逊的无人超市至今仍处于员工内测阶段;阿里和京东的无人超市虽然率先向公众开放,但顾客体验却也不敢恭维。如果你等不及无人超市的大规模落地,那就从这篇教程出发,自己先开上一家简易版的无人超市吧!
( 责任编辑:创新创业)